ChatGPT의 도입으로 많은 사람들이 이를 어떻게 생산성 향상에 활용할까 고민을 하고 있다. 대표적으로 네이버 클로바 노트를 이용하여 녹음된 회의록을 글로 작성한다던가, PDF 통번역 및 인식을 통해서 긴 논문이나 자료를 짧게 요약한다.

● AI는 정말 비싼 기술
하지만 이런 ChatGPT는 월 20달러를 받아도, 아니 월 60달러를 받아도 손익분기점에 도달하지 못한다고 OpenAI가 인터뷰에서 언급했다. 왜 그럴까? 기존의 메모리 및 데이터 보관, 처리 방식으로는 방대한 AI 서비스를 제공하기에 효율이 떨어지기 때문이다.
과거 컴퓨터가 처음 탄생하며 등장한 폰 노이만 방식의 컴퓨팅 시스템은 모든 것이 개인 컴퓨터 내에서 이루어졌다. 컴퓨터 내에서 무언가를 입력하면 컴퓨터 내의 작업대인 메모리에 작업들을 올려놓고, CPU라는 프로세서를 통해 계산한다. 마지막으로 그 결과가 하드디스크에 저장되는 방식이다.
하지만 인터넷과 모바일 생태계가 발전하면서 자료의 유동성이 활발해지기 시작했다. 더이상 모든 자료와 계산은 내 컴퓨터 내에서만 이루어지는 것이 아니었다. 다른 컴퓨터, 다른 기기와의 상호작용이 중요해지기 시작했고 무언가 중앙화된 데이터 정류장, 주차장이 필요했다.

● 데이터 센터는 비효율이 내재되어있다
막대한 양의 데이터를 처리하기 위해 무식한 방법으로 초대량의 메모리를 건물 내에 꽂기 시작했고, 24시간 365일 전기가 끊이지 않는 방식으로 데이터 센터를 운영했다. 그렇게 많은 메모리 반도체 관련 기업들이 이러한 흐름에 혜택을 받았다.
그리고 ChatGPT가 촉발한 또 한 번의 변곡점, AI 시대가 돌입했다. 단순 데이터의 상호작용 뿐만 아니라 AI 처리방식은 그간 학습한 내용을 기반으로 질문자의 의도를 파악하여 원하는 답변을 낸다.
- 기존 : A의 개인정보 갖고와 → A 정보 있는 위치로 가서 데이터를 불러옴
- AI 방식 : 워렌 버핏의 투자법에 대해 정리해줘 → 데이터 센터 속 워렌버핏 관련 뉴스, 책, 논문, 블로그 정리글, 유튜브 데이터를 모두 찾아서 투자법에 관한 내용만 추출 후 답변함
두 가지 사례를 비교하더라도 데이터를 찾고자 하는 AI가 얼마나 많은 곳을 왔다갔다할지 감이 온다. 심지어 이게 어려운 질문일까? 절대 아니다. 그럼에도 불구하고 엄청난 수준의 처리 방식을 요구하고, 이는 병목현상으로 이어진다.
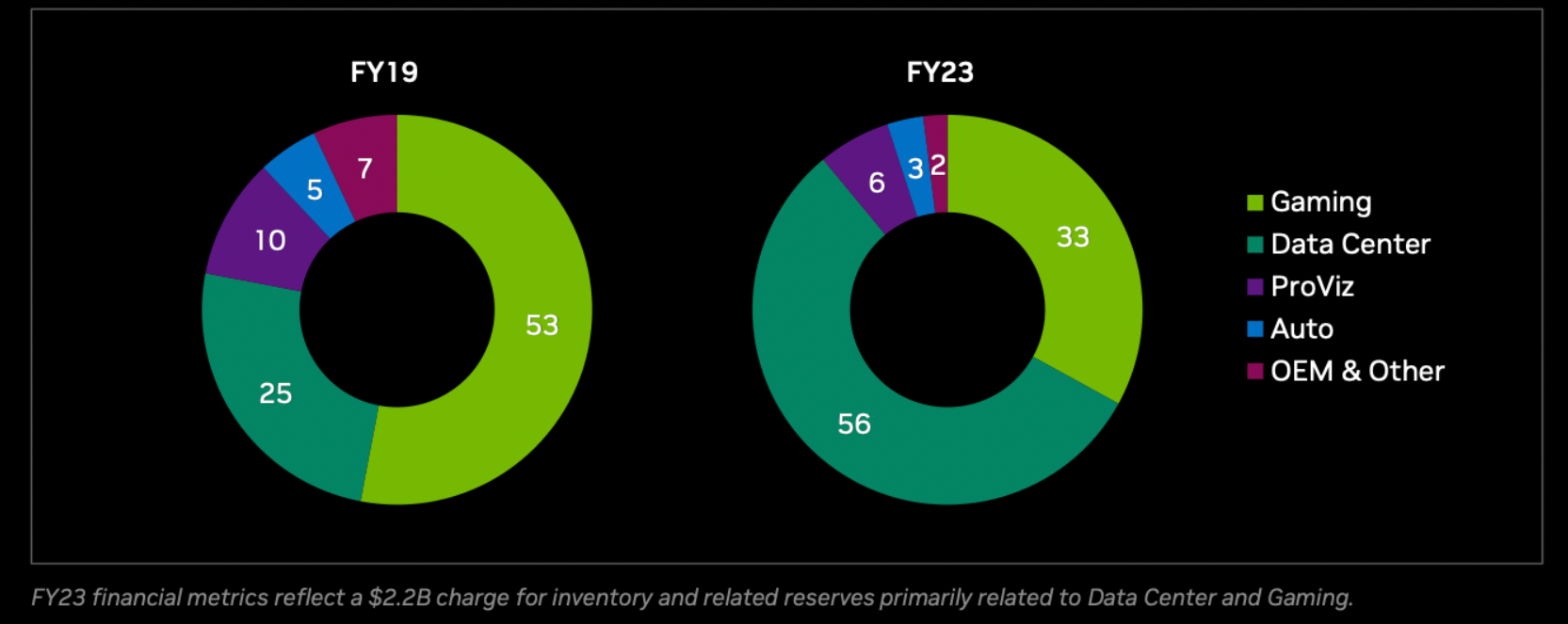

● GPU 수요
그렇기에 여러 명령어를 동시에 처리 가능한 GPU가 주목을 받고 있다. 과거 GPU는 CPU대비 낮은 성능의 코어였지만, 지금은 기술이 발달해서 코어 성능 또한 많이 올라왔고 덕분에 각 코어별 계산 능력도 뛰어나졌다.
NVIDIA는 과거부터 자신들이 잘하는 멀티미디어 처리 방식을 집중하며 데이터 센터의 병목 현상을 해결하겠다고 방향을 잡았었는데, 그것이 현재 AI 트렌드와 맞물렸다. 현재 엔비디아의 매출을 보면 50% 이상이 데이터 센터 관련 매출임을 알 수 있다. AMD 또한 42%가 데이터센터로부터 나온 매출이다.

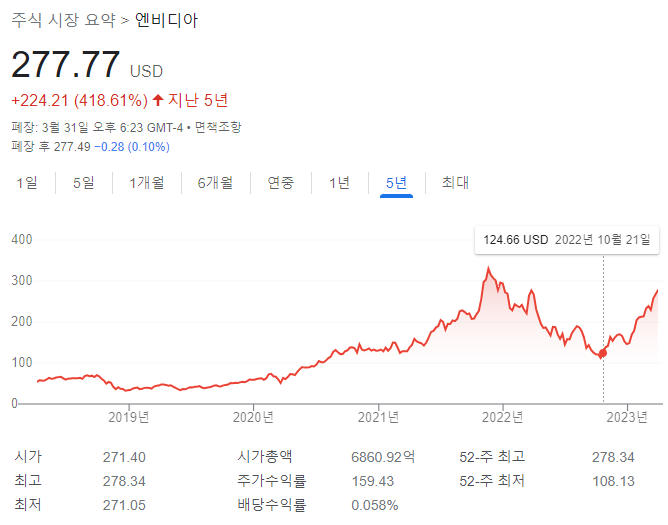

● 이미 반영된 주가들
삼성전자와 SK하이닉스 또한 이전부터 준비한 PIM(Processing-in-memory)반도체를 준비하고 2021년 10월 AMD의 GPU 'MI-100' 가속기 카드에 탑재되는 등 대응에 나서고 있다. 우리나라는 우리나라가 잘하는 메모리 반도체의 관점에서 문제를 해결하고 있음. NVIDIA나 AMD에는 메모리 반도체가 탑재되기 때문에 삼성전자나 SK 하이닉스 또한 AI시대에 호혜를 받을 가능성이 높다. 앞선 기업들보다 먹을 파이는 적겠지만 말이다...
물론 이러한 접근 방식들이 기존의 병목 현상을 효율적으로 해결해줄 것인지는 지켜봐야한다. 아직까지는 기존의 틀에서 크게 벗어나지 않았기 때문이다. 비효율은 잔재한다. 새로운 정답이 나타날지...
'경제 및 재테크 정리' 카테고리의 다른 글
| 개인연금과 연금저축의 차이 (0) | 2023.04.26 |
|---|---|
| 하워드 막스 메모 SVB(실리콘밸리은행) 파산으로부터의 배움 (0) | 2023.04.18 |
| 토스 뱅크런 가능성? 위험성 따져보기 (0) | 2023.03.27 |
| 신한 산리오 카드 혜택, 배송일, 서류 전산처리, 미성년자 발급방법 (1) | 2023.03.19 |
| 담당자 꼭 보셈) sc제일은행 제일EZ통장 개설 후기 및 우대금리 적용여부 확인법 (1) | 2023.02.28 |
